GANs中的明星StarGAN:使用单一模型执行多个域的图像转换,GAN之父点赞
2017年可谓“GANs之年”,各种基于GANs的模型和变化层出不穷。近日,来自韩国首尔大学、Naver等研究者发布了一篇“StarGAN:Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation”的文章,下面AI科技评论和大家来看下这篇论文。
论文摘要:
最近的研究表明在两个领域的图像转化方面取得了显着的成功。 然而,现有的方法在处理两个以上的域时在可伸缩性和鲁棒性上存在局限,原因在于应该为每一对图像域独立建立不同的模型。为了解决这个限制,我们提出了StarGAN,这是一种新颖且可扩展的方法,可以仅使用一个模型来执行多个域的图像到图像的转换。StarGAN这样一个统一的模型体系架构让我们可以同时训练单个网络中具有不同域的多个数据集,这导致StarGAN的图像转化结果比现有模型质量更高,并具有将输入图像灵活转化成任何期望目标域的新颖能力。我们凭经验证明了我们的方法在面部属性转移和面部表情合成任务上的有效性。

(图2:StarGAN进行多个域的图像转换)
图2为在CelebA数据集上通过传递从RaFD数据集中学习到的知识,进行多领域图像到图像的转换结果。第一列和第六列显示输入图像,而其余的列是由StarGAN生成的图像。 (值得注意的是,图像由一个单一的生成器网络产生,如愤怒、快乐和恐惧等面部表情标签来自RaFD,而不是CelebA。)
图像到图像转换的任务是将给定图像的某个特定属性改变为另一种属性,例如将人的面部表情从微笑改变为皱眉(见图2)。而在引入生成对抗网络(GAN)之后,这个任务进一步升级,生成结果包括改变头发颜色、从边缘映射重建照片、改变风景图像的季节等。
给定来自两个不同域的训练数据,这些模型将学习如何将图像从一个域转换到另一个域中。在这里,我们将术语属性用诸如头发颜色、性别或年龄等这些图像中固有意义的特征来表示,并将属性值作为属性的特定值,例如头发颜色:黑色/金色/棕色,或性别:男性/女性。我们进一步将域表示为一组共享相同属性值的图像。例如,女性的图像可以代表一个域,而男性的图像则代表另一个域。
某些图像数据集会带有一些标注属性,例如,CelebA数据集包含40个与面部属性相关的标签,如头发颜色、性别和年龄等,而RaFD数据集有8个面部表情标签,如“开心”、“愤怒”、“悲伤”等。这些设置属性使我们能够执行更多有趣的任务,我们称之为多域的图像到图像转换,即根据来自多个域的属性来变换图像,如图2中的前五列显示了一个CelebA图像是如何按照“金发”、“性别”、“老年”和“苍白的皮肤”四这个域中来进行转换的。我们还可以进一步扩展到从不同的数据集中训练多个域,如联合训练CelebA和RaFD图像,如图2最右一列就是使用在RaFD训练过程中学习的特征来改变CelebA图像的面部表情。
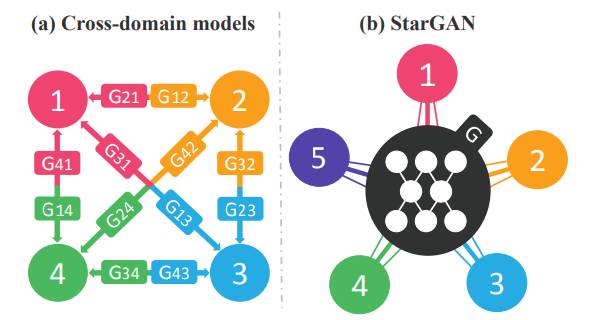
(图3:StarGAN与Cross-domain models的区别)
然而,目前的模型在这种多域的图像转换任务中效率不高且效果低下。它们效率不高主要是为了学习k个域之间的所有映射,必须训练k(k-1)个生成器,如图3所示,左边表明了在4个不同的域中进行图像转换需要训练12个不同的生成器,而它们效果也不是很好。即便存在诸如面部形状这样可以从所有域的图像中学习的全局特征,每个生成器都不能充分利用整个训练数据,而只能从k个中的两个域中进行学习,这也进一步限制了生成图像的质量。此外,由于每个数据集已经是部分标注的,所以他们无法联合训练来自不同数据集的域。
基于此,我们提出StarGAN,一个能够学习多个域之间相互映射的生成对抗网络。如上图右侧所示,我们的模型可以从多个域中提取训练数据,并仅使用一个生成器就可以学习所有可用域之间的映射。这个想法很简单:我们的模型将图像和域信息作为输入而不是学习固定转换(例如,黑色到金色的头发),并学习将输入图像灵活地转换到相应的域。我们使用标签(例如,二进制或onehot向量)来表示域信息。在训练中,我们随机生成一个目标域标签,并训练模型以灵活地将输入图像转换到目标域。这样,我们可以控制域标签,并在测试阶段将图像转换成任何期望的域。
我们还提出了一种简单而有效的方法,这一方法可以通过向域标签添加一个掩码向量,来实现不同数据集的域之间的联合训练。这一方法确保模型可以忽略未知的标签并聚焦于特定数据集提供的标签。这样,我们的模型可以很好地完成如使用从RaFD学习的特征来合成CelebA图像的面部表情的任务(如图2最右一列)。据我们所知,我们的该项研究是第一个在不同数据集上成功执行多域图像转换的研究。
总的来说,我们的贡献如下:
我们提出了一种全新的生成对抗网络StarGAN,该网络只使用一个生成器和一个鉴别器来学习多个域之间的映射,并从各个域的图像中有效地进行训练;
我们演示了如何使用掩模向量方法(mask vector method)成功学习多个数据集之间的多域图像转换,并使得StarGAN控制所有可用的域标签;
我们使用StarGAN进行面部属性转换和面部表情合成任务,并对结果进行了定性和定量分析,结果显示其优于基准线模型。
反响:Ian GoodFellow点赞,网友热议

不出所料,这篇论文被GAN的提出者Ian Goodfellow发推点赞,重点提了StarGAN在多个域中用非监督学习方法进行转换的成果(之前的研究是在两个域中进行转换)。
而在Reddit的Machine Learning版块上,这篇论文也引起了热烈讨论,Reddit指数直逼一千。AI科技评论摘录了几条关于这篇文章的评价如下:
@ReginaldIII:
很酷的研究。 令人惊讶的是,他们没有在相关的工作中引用任何Google的神经转换的论文。 将多个生成器模型编码到一个共同的空间并在整个集合上进行训练,这种想法并不是新鲜。 尽管GAN的应用给出了很好的结果。
@ajinkyablaze:
对于那些你的角色顶着丑陋的头像的视频游戏来说是个不错的东西。
@Reiinakano对这条评论进行了回复:
说实话,这件事正在进行,我敢说现在已经有一个非常清晰的路径来生成恶搞奥巴马(AI科技评论注:原文为“Obama punching babies”,punching babies为“喝酒”或“聚会”的代名词)的视频。
@bigassholeredditor :
这看起来很棒。你们有预训练的模型吗?
第一作者@Yunjey回复:
我们很快将上传预训练的模型。
于是下面就被“一月内求通知”刷了屏。
@abhik_singla:
这与Pix2Pix方法有什么区别?
@ProgrammerChilli回复:
论文中有提到。简单说,Pix2pix要求明确地学习从一个域到另一个域的任何转换,StarGAN可以一次学习几个领域,并从任何领域转换到另一个领域。 我想,这就是它为什么用“STAR”命名的原因吧?
论文下载地址:https://arxiv.org/pdf/1711.09020.pdf
GANs中的明星StarGAN:使用单一模型执行多个域的图像转换,GAN之父点赞相关推荐
- CVPR 2019 | 旷视提出超分辨率新方法Meta-SR:单一模型实现任意缩放因子
点击我爱计算机视觉标星,更快获取CVML新技术 CV君按:图像超分辨率(Super-Resolution,SR )的研究由来已久,但近两年来随着深度学习在该领域的成功应用,工业界的研究突然火了起来,互 ...
- CVPR | 旷视提出Meta-SR:单一模型实现超分辨率任意缩放因子
点上方蓝字计算机视觉联盟获取更多干货 在右上方 ··· 设为星标 ★,与你不见不散 编辑:Sophia 计算机视觉联盟 报道 | 公众号 CVLianMeng 转载于 :旷视 [人工智能资源(书籍 ...
- 看EyeEm如何在产品开发中整合、运用深度学习模型
原文:One Model At A Time: Integrating And Running Deep Learning Models In Production At EyeEm 作者:Miche ...
- 在PyTorch中使用卷积神经网络建立图像分类模型
概述 在PyTorch中构建自己的卷积神经网络(CNN)的实践教程 我们将研究一个图像分类问题--CNN的一个经典和广泛使用的应用 我们将以实用的格式介绍深度学习概念 介绍 我被神经网络的力量和能力所 ...
- AI周报丨中文巨量模型源1.0比GPT-3强在哪里?;谷歌用协同训练策略实现多个SOTA,单一ViT模型执行多模态多任务
01 # 行业大事件 语言大模型的终极目标是什么? 在自然语言处理(NLP)领域,暴力美学仍在延续. 自 2018 年谷歌推出 BERT(3.4 亿参数)以来,语言模型开始朝着「大」演进.国内外先后出 ...
- 设计模式中遵循的原则:单一职责、开发-封闭、依赖倒转
设计模式中遵循的原则:单一职责.开放-封闭.依赖倒转 单一职责原则 一个类而言,应该仅有一个引起它变化的原因. 如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会消弱或者抑制这 ...
- 详解Linux2.6内核中基于platform机制的驱动模型 (经典)
[摘要]本文以Linux 2.6.25 内核为例,分析了基于platform总线的驱动模型.首先介绍了Platform总线的基本概念,接着介绍了platform device和platform dri ...
- java if在内存中_全面理解Java内存模型
Java 内存模型的抽象 在 java 中,所有实例域.静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用"共享变量"这个术语代指实例域,静态域和数组元素).局部变量( ...
- 详解Linux2.6内核中基于platform机制的驱动模型
原文地址:详解Linux2.6内核中基于platform机制的驱动模型 作者:nacichan [摘要]本文以Linux 2.6.25 内核为例,分析了基于platform总线的驱动模型.首先介绍了P ...
最新文章
- 查看mysql数据库及表编码格式
- 有return的情况下try catch finally的执行顺序
- mysql 性能和安全性_从源码解读Mysql 5.7性能和数据安全性的提升
- 雅虎的Web优化最佳实践
- mysql 不通过关联查询表_mysql中多表不关联查询的实现方法详解
- Android 基础 —— 活动的生存周期
- python中osgeo库使用教程链接
- 实验一 线性表的顺序存储与实现_【自考】数据结构中的线性表,期末不挂科指南,第2篇
- 兔子--百度地图所需的jar+so下载地址
- 百度云服务器bcc搭建php环境,使用百度云服务器BCC经验谈
- 这组三八妇女节海报素材psd模板,你给打几分?
- java 创建ppt文件怎么打开文件,JAVA读取PPT文件
- Linux下使用脚本安装和升级pip
- cocos2d-x 执行在 genymotion上面
- Solr应用之电商商品搜索备忘
- Map<String,Object> map=new HashMap<String,Object>详解
- postgresql could not connect to server
- 生活广场远程预付费电能管理系统的设计与应用
- 毫米波技术入局智能家居,是大材小用还是技术革命?
- Android音频可视化
热门文章
- Java web speach api_Web Speech API - 语音文本转换的Web解决方案
- 大数据实验报告总结体会_大数据挖掘流程及方法总结
- f150platinum_新款福特F150PLATINUM精英版皮卡超强越野实力展示
- 辽师836c语言真题,2018年武汉科技大学考研真题硕士研究生入学考试试题
- linux下如何更新镜像源(ubuntu 10.04 为例),Ubuntu 10.04 更新源补充
- unity 天空盒_使用Substance in Unity搭建Unity和SP的live link实时互通环境
- python 修改字符串中的某个单词_python Pandas替换字符串中的单词
- JavaScript是如何工作的:编写自己的Web开发框架 + React及其虚拟DOM原理
- 中介者模式 调停者 Mediator 行为型 设计模式(二十一)
- 自定义LayoutManager实现最美应用列表