OpenCV——KNN分类算法 摘
KNN近邻分类法(k-Nearest Neighbor)是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本周围K个最近邻以给出该样本的相应值。这种方法有时候被称作“基于样本的学习”,即为了预测,我们对于给定的输入搜索最近的已知其相应的特征向量。
简单说来就是从训练样本中找出K个与其最相近的样本,然后看这K个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。
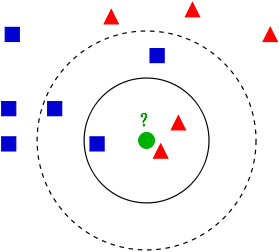
有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
判别上图中那个绿色的圆是属于哪一类数据就从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
KNN算法的步骤
- 计算已知类别数据集中每个点与当前点的距离;
- 选取与当前点距离最小的K个点;
- 统计前K个点中每个类别的样本出现的频率;
- 返回前K个点出现频率最高的类别作为当前点的预测分类。
- 训练KNN模型
bool CvKNearest::train( const CvMat* _train_data, const CvMat* _responses,const CvMat* _sample_idx=0,bool is_regression=false, int _max_k=32, bool _update_base=false );
这个类的方法训练K近邻模型。
它遵循一个一般训练方法约定的限制:只支持CV_ROW_SAMPLE数据格式,输入向量必须都是有序的,而输出可以 是 无序的(当is_regression=false),可以是有序的(is_regression = true)。并且变量子集和省略度量是不被支持的。
参数_max_k 指定了最大邻居的个数,它将被传给方法find_nearest。
参数 _update_base 指定模型是由原来的数据训练(_update_base=false),还是被新训练数据更新后再训练(_update_base=true)。在后一种情况下_max_k 不能大于原值, 否则它会被忽略。
- 寻找输入向量的最近邻
float CvKNearest::find_nearest( const CvMat* _samples, int k, CvMat* results=0, const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0 ) const;
参数说明:
- samples为样本数*特征数的浮点矩阵;
- K为寻找最近点的个数;results与预测结果;
- neibhbors为k*样本数的指针数组(输入为const,实在不知为何如此设计);
- neighborResponse为样本数*k的每个样本K个近邻的输出值;
- dist为样本数*k的每个样本K个近邻的距离。
对每个输入向量(表示为matrix_sample的每一行),该方法找到k(k≤get_max_k() )个最近邻。在回归中,预测结果将是指定向量的近邻的响应的均值。在分类中,类别将由投票决定。
对传统分类和回归预测来说,该方法可以有选择的返回近邻向量本身的指针(neighbors, array of k*_samples->rows pointers),它们相对应的输出值(neighbor_responses, a vector of k*_samples->rows elements) ,和输入向量与近邻之间的距离(dist, also a vector of k*_samples->rows elements)。
对每个输入向量来说,近邻将按照它们到该向量的距离排序。
对单个输入向量,所有的输出矩阵是可选的,而且预测值将由该方法返回。
一般的分类模型建立的步骤,分类一般分为两种:
- 决策树归纳(消极学习法):先根据训练集构造出分类模型,根据分类模型对测试集分类。
消极学习法在提供训练元组时只做少量工作,而在分类或预测时做更多的工作。KNN就是一种简单的消极学习分类方法,它开始并不建立模型,而只是对于给定的训练实例点和输入实例点,基于给定的邻居度量方式以及结合经验选取合适的k值,计算并且查找出给定输入实例点的k个最近邻训练实例点,然后基于某种给定的策略,利用这k个训练实例点的类来预测输入实例点的类别。
- 基于实例的方法:推迟建模,当给定训练元组时,简单地存储训练数据(或稍加处理),一直等到给定一个测试元组。
转载于:https://www.cnblogs.com/farewell-farewell/p/5910834.html
OpenCV——KNN分类算法 摘相关推荐
- python分类算法_用Python实现KNN分类算法
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 KNN分类算法应该算得上是机器学习中最简单的分类算法了,所谓KNN即为K-NearestNeighbor(K个最邻 ...
- KNN 分类算法原理代码解析
作者 | Charmve 来源 | 迈微AI研习社 k-最近邻算法是基于实例的学习方法中最基本的,先介绍基x`于实例学习的相关概念. 基于实例的学习 已知一系列的训练样例,很多学习方法为目标函数建立起 ...
- 用Python开始机器学习(4:KNN分类算法)
转自: http://blog.csdn.net/lsldd/article/details/41357931 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classi ...
- k近邻算法(KNN)-分类算法
k近邻算法(KNN)-分类算法 1 概念 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. k-近邻算法采用测量不同特征值之间的 ...
- 利用python语言实现分类算法_使用python实现kNN分类算法
k-近邻算法是基本的机器学习算法,算法的原理非常简单: 输入样本数据后,计算输入样本和参考样本之间的距离,找出离输入样本距离最近的k个样本,找出这k个样本中出现频率最高的类标签作为输入样本的类标签,很 ...
- 《机器学习实战》学习总结(一)KNN分类算法原理
kNN分类算法属于有监督类学习算法. 该分类算法不需要训练算法,直接对待分类点进行决策分类. 算法实现过程如下: 1.计算测试点与已知类别数据集中点的距离: 2.对距离进行排序(递增). 3.选取与测 ...
- Python实现knn分类算法(Iris 数据集)
1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定 ...
- 从原始文档到KNN分类算法实现(一)
版权声明:本文为博主原创文章,未经博主允许不得转载. 建立原始文档 ~/corpus/C1下建三个文件:0,1,2.内容分别为: 0 眼睛 明亮 健康 身体 发达 1 高大 身材 胳膊 勇猛 四肢 2 ...
- knn分类算法实现手写体数字识别python
之前写过knn分类算法代码,想把knn用于设别手写体数字,看下正确率. 大概思路:获取图片(可以自己写,我之前有写过黑白图片转文本的代码,也可以网上找,反正数据量大会更好)->转成文本-> ...
最新文章
- 同时进科俩博士,一个被围着宠着、一个却被当成空气;凭什么?
- 【linux+C】神器 vim + 指针相关客串
- [考试]20151019图论
- 使用feof()判断文件结束时会多输出内容的原因
- Netflix的Hystrix使用教程
- Python高阶——argparse(命令行与参数解析)
- 在tunnelbroker为服务器IP建立IPV6 Tunnel
- Visio实现箭头反向
- 全国最大SLAM开发者学习交流社区 欢迎加入
- UE4虚拟摄像头插件
- GTP编译报错,需要增加IBUF
- Win10笔记本WIFI的标志突然变成了一个地球的解决方案(二)
- html5四季特点,美国一年四季天气特点介绍
- Hadoop部署(一) Ubantu Java JDK安装
- 认认真真推荐9个高质量公众号
- 以大多数人的努力程度之低,根本轮不到拼智商
- opencv RGB与HSV转化
- 苹果4s怎么越狱教程_苹果手机:iOS12怎么降级iOS12一键刷机降级教程
- 充电枪cp信号控制板_一种电动汽车交流充电系统的CP信号电压检测方法及装置与流程...
- Centos 7.2内核版本升级(无外网)